Recruiting Large Groups¶
Running social experiments often requires many users to participate at the same time. So when are the greatest number of workers simultaneously available on Mechanical Turk?
The answer to this question can help in general to guide when to post HITs, However, social experiments often use tasks where many workers must be online at the same time, such as for studying simultaneous interaction between many participants and sometimes this number must be pretty large. In order to do this, we typically schedule a time in advance and notify users to show up at that time.
This scheduling has generally been ad hoc, but in a few cases we’ve collected some extra data from workers about their availability, normalized by timezone. The following graph shows the distribution of over 1,200 workers available in each hour, per their reports:
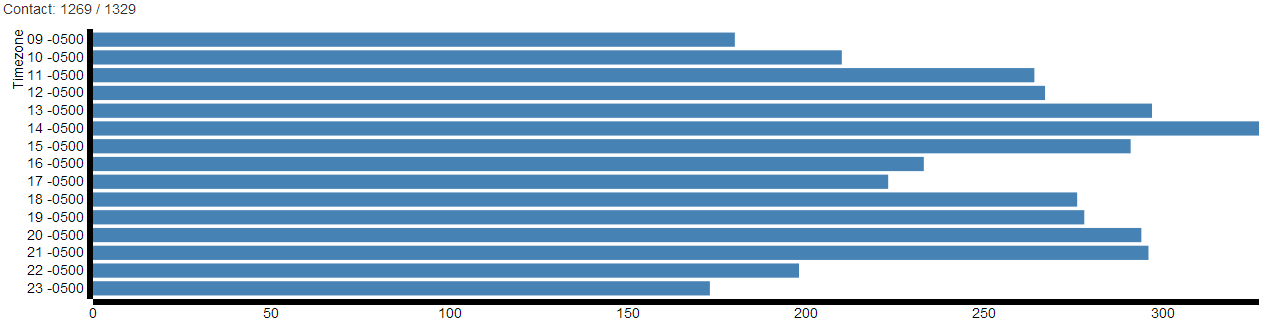
The buckets are shown from 9AM to 11PM GMT -5, but are computed from the users’ original timezones. A few caveats: the graph is for a few hundred US workers only, and the method of collection could be biased by time of day effects (the time of day that we collected the data will affect the time preferences of users.) However, the pattern squares with previous anecdotal observations that either the mid-afternoon or late evening are the best time to post group tasks, and that people don’t tend to be online as much in the morning or at dinner time.
What happens when one starts using this panel of workers? After running a few dozen synchronous experiments all at 2PM EDT, the distribution of the remaining times now looks like the following, with just over 900 workers available. (For now, we are using each worker only once.)
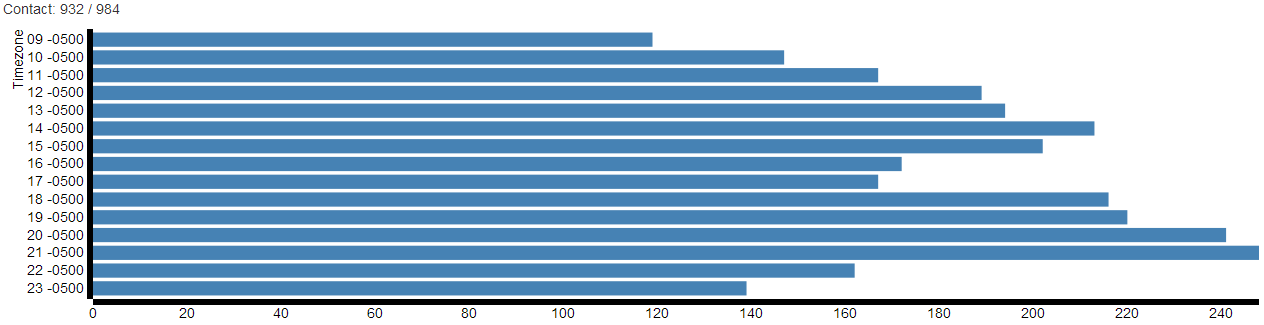
As you can see, we’ve drastically reduced the number of workers available at 2PM, while not really affecting the number of workers available at 9PM. In order to get the maximum number of workers online simultaneously for our next synchronous batch, we’d do best to shoot for 9PM instead.
Keep in mind that there can be strong time-of-day effects here, as there are dissimilar populations likely to be online at certain times. Because of this, it’s best to randomize over all of our possible experimental treatments simultaneously, so that the effect hits all of them. Collecting this time-of-day data is almost essential for overcoming the significant challenges in scheduling a large number of unique users all online at the same time.
The graphs above were generated by the panel recruiting section of TurkServer’s admin interface.
Example of simultaneous recruiting¶
The following screenshot shows a recent study we deployed using this method, pulling out all the stops for this one, resulting in sessions with 100 participants arriving within 2 minutes of each other. They all participated for over one hour.
![]()
In our case, we randomized them into different-sized groups for this study. The simultaneous recruitment was necessary for all of our treatments to experience the same population, and the biggest group of users had 32 participants.
The experiment design triangle¶
Perhaps you’ve heard of the project management triangle: it’s often been encapsulated as “fast, good, or cheap: pick two” because it’s been invariably impossible to satisfy all three in executing projects.
In designing web-based behavioral experiments, there is a generally a similar triangle of three desirable properties that are very difficult to satisfy simultaneously:
- Large sample size: desirable to increase experiment power
- Large number of simultaneous arrivals: whether for synchronous experiments or to minimize time-of-day effects across treatments (as above)
- Unique participants:i.e. those who haven’t seen the study before
When running large experiments that are synchronous or require extensive randomization, and that are constrained to unique participants, one will naturally run into the sample size ceiling. It is feasible to recruit about 1500 to 2000 active workers on MTurk on any given week, but fewer and fewer of them are available at the same time as you schedule your experiments.
Alternatively, this means that if you can design your experiments to be less sensitive to repeat participation, it’s possible to have a lot of people participate and also gather a lot of data. This is possible for some experiments, but it can be challenging to ensure that the design is answering the right question, and that participants aren’t being primed from the past or sensitive to experience.
Finally, the vast majority of online studies that are done don’t require simultaneous arrivals because either they are for single users or they are not scheduled consistently at the same time of day. Without this constraint, it’s possible to have many unique participants with a sample size of a couple thousand or more, but one should be careful that region and time-of-day effects are being controlled for.